3. ヒストグラム#
3.1. 概要#
ヒストグラム(Histogram) とは,量的変数に対して,分布の形状を 長方形の組合せ で表すグラフです. 横軸に変数の 区間 ,縦軸にその区間に属するデータの数( 度数 )を取ります. 柱状図 とも呼ばれます. 量的変数の分布を見る際,利用頻度が高い図です.
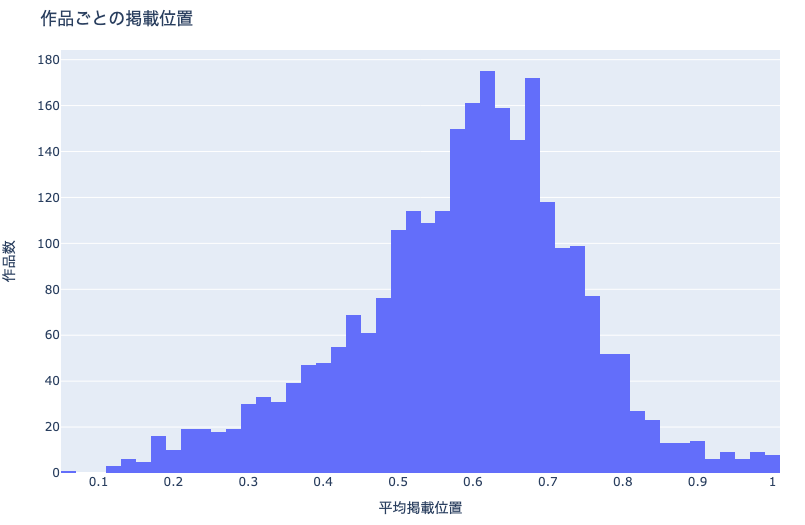
例えば上図は,マンガ作品ごとの平均掲載位置の分布を表したヒストグラムです.0.6から0.7にピークがあることがわかります.
ヒストグラムには様々な種類がありますが,ここでは累積ヒストグラムと積上げヒストグラムを紹介します.
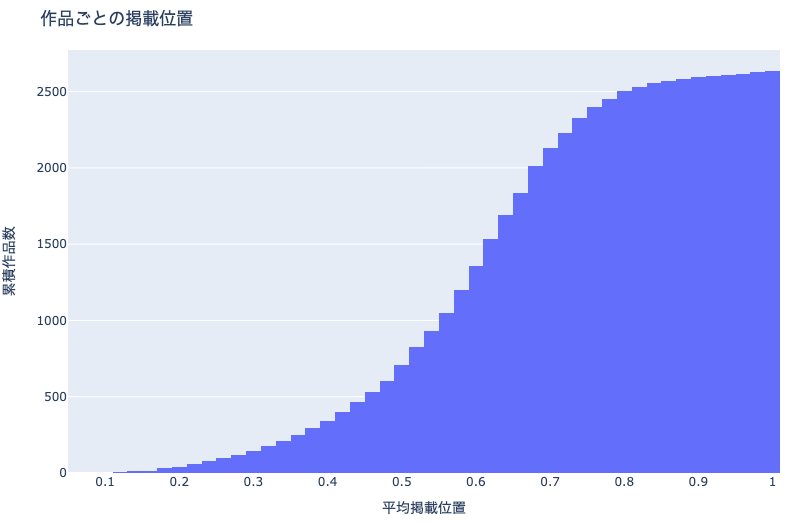
累積ヒストグラム とは,下図のように累積分布を表現したヒストグラムです.これにより 特定の値以下(以上) のデータがどの程度存在するかを確認することができます.
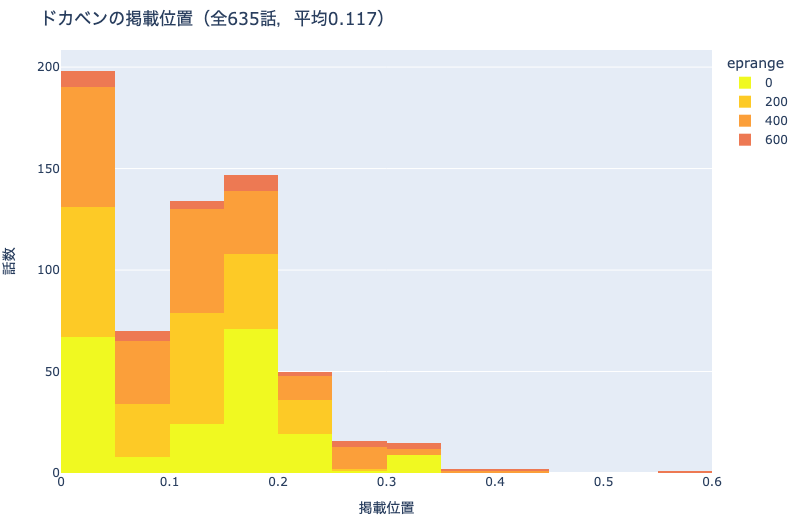
積上げヒストグラムとは,下図のように横軸とは他の変数によって度数を分割し,縦に積上げたヒストグラムです.これにより,分布を構成する要素の内訳を確認しやすくなります.
3.2. Plotlyによる作図方法#
Plotlyでは,plotly.express.histogram()でヒストグラムを作成可能です.
import plotly.express as px
fig = px.histogram(df, x='col_x')
上記の例では,dfのcol_x列をX軸,その度数をY軸に取ったヒストグラムのオブジェクトfigを作成します.また,
fig = px.histogram(df, x='col_x', cumulative=True)
cumulative=Trueオプションを指定することで,累積ヒストグラムを作図可能です.更に,
fig = px.histogram(df, x='col_x', color='col_stack', barmode='stack')
barmode='stack'を指定することで,col_stack列に関する積み上げヒストグラムを作図可能です.
もちろん,cumulativeとの組み合わせて使うこともできます.
3.3. MADB Labを用いた作図例#
3.3.1. 下準備#
import pandas as pd
import plotly.express as px
import warnings
warnings.filterwarnings('ignore')
# 前処理の結果,以下に分析対象ファイルが格納されていることを想定
PATH_DATA = '../../data/preprocess/out/episodes.csv'
# Jupyter Book用のPlotlyのrenderer
RENDERER = 'plotly_mimetype+notebook'
# 平均掲載位置を算出する際の最小連載数
MIN_WEEKS = 5
def show_fig(fig):
"""Jupyter Bookでも表示可能なようRendererを指定"""
fig.update_layout(margin=dict(t=50, l=25, r=25, b=25))
fig.show(renderer=RENDERER)
df = pd.read_csv(PATH_DATA)
3.3.2. 掲載位置の分布#
MIN_WEEKS以上連載したマンガ作品の平均掲載位置の分布を見てみます.
df_plot = \
df.groupby(['mcname', 'cname', 'creator'])['pageStartPosition']\
.agg(['count', 'mean']).reset_index()
df_plot = df_plot[df_plot['count'] >= MIN_WEEKS]\
.reset_index(drop=True)
fig = px.histogram(
df_plot, x='mean', title='作品ごとの掲載位置')
fig.update_xaxes(title='平均掲載位置')
fig.update_yaxes(title='作品数')
show_fig(fig)
0.6 - 0.7付近にピークのある分布であることがわかります.
fig = px.histogram(
df_plot, x='mean', cumulative=True,
title='作品ごとの掲載位置')
fig.update_xaxes(title='平均掲載位置')
fig.update_yaxes(title='累積作品数')
show_fig(fig)
累積ヒストグラムで見ると,平均掲載位置を低いことがどの程度珍しいかわかります.平均掲載位置が0.5以下の作品(つまり,平均的に雑誌の前半に掲載されることが多い作品)は半分以下です.
具体的にはどのような作品の平均掲載位置が低いのでしょうか?
df_plot.sort_values('mean').reset_index(drop=True).head(10)
| mcname | cname | creator | count | mean | |
|---|---|---|---|---|---|
| 0 | 週刊少年チャンピオン | ピクル | 板垣恵介 | 7 | 0.069270 |
| 1 | 週刊少年サンデー | 一球さん | 水島新司 | 127 | 0.115419 |
| 2 | 週刊少年チャンピオン | ドカベン | 水島新司 | 635 | 0.116675 |
| 3 | 週刊少年ジャンプ | ONE PIECE | 尾田栄一郎 | 890 | 0.128448 |
| 4 | 週刊少年チャンピオン | 刃牙道 | 板垣恵介 | 167 | 0.133967 |
| 5 | 週刊少年チャンピオン | 弱虫ペダル | 渡辺航 | 461 | 0.135877 |
| 6 | 週刊少年チャンピオン | 範馬刃牙 SON OF OGRE | 板垣恵介 | 314 | 0.137266 |
| 7 | 週刊少年サンデー | ちくちくウニウニ | 吉田戦車 | 16 | 0.140041 |
| 8 | 週刊少年チャンピオン | ダントツ | 水島新司 | 59 | 0.142519 |
| 9 | 週刊少年サンデー | 金色のガッシュ!! | 雷句誠 | 323 | 0.145896 |
各雑誌を代表するような先生方の作品であることがわかります.ちなみにピクルは板垣先生のバキシリーズのスピンオフです.
3.3.3. 長期連載作品の掲載位置の分布#
長期連載した人気作品ほど掲載位置が上位なのでしょうか?
これを検証するため,合計連載週数が多い10作品に対して,それぞれ掲載位置の分布を図示します.
df_tmp = \
df_plot.sort_values(['count'], ascending=False, ignore_index=True)\
.head(10)
df_tmp
| mcname | cname | creator | count | mean | |
|---|---|---|---|---|---|
| 0 | 週刊少年ジャンプ | こちら葛飾区亀有公園前派出所 | 秋本治 | 1866 | 0.612542 |
| 1 | 週刊少年マガジン | はじめの一歩 | 森川ジョージ | 1184 | 0.345121 |
| 2 | 週刊少年サンデー | 名探偵コナン | 青山剛昌 | 1008 | 0.175239 |
| 3 | 週刊少年ジャンプ | ONE PIECE | 尾田栄一郎 | 890 | 0.128448 |
| 4 | 週刊少年サンデー | MAJOR | 満田拓也 | 748 | 0.261425 |
| 5 | 週刊少年ジャンプ | NARUTO-ナルト- | 岸本斉史 | 722 | 0.191761 |
| 6 | 週刊少年ジャンプ | BLEACH | 久保帯人 | 715 | 0.411773 |
| 7 | 週刊少年ジャンプ | 銀魂 | 空知英秋 | 652 | 0.447538 |
| 8 | 週刊少年チャンピオン | ドカベン | 水島新司 | 635 | 0.116675 |
| 9 | 週刊少年ジャンプ | ジョジョの奇妙な冒険 | 荒木飛呂彦 | 594 | 0.625421 |
cnames = df_tmp.sort_values('mean')['cname'].values
for cname in cnames:
df_c = df[df['cname']==cname].reset_index(drop=True)
pos = df_c['pageStartPosition'].mean()
n = df_c.shape[0]
fig = px.histogram(
df_c, x='pageStartPosition', nbins=20,
title=f'{cname}の掲載位置(全{n}話,平均{pos:.3f})')
fig.update_xaxes(title='掲載位置')
fig.update_yaxes(title='話数')
show_fig(fig)