5. 箱ひげ図#
5.1. 概要#
箱ひげ図(Box Plot) とは,主に量的変数に対して,分布の形状を 箱 とそこから伸びる 直線 で表現したグラフです. 箱は 四分位数 を表し,直線の長さは 最大値・最小値 を表します. 分布の細かい情報が削ぎ落とされてしまいますが,複数の分布を比較する際は非常に便利です. 後述するバイオリンプロットやストリッププロットと組合せて描画されることもあります.
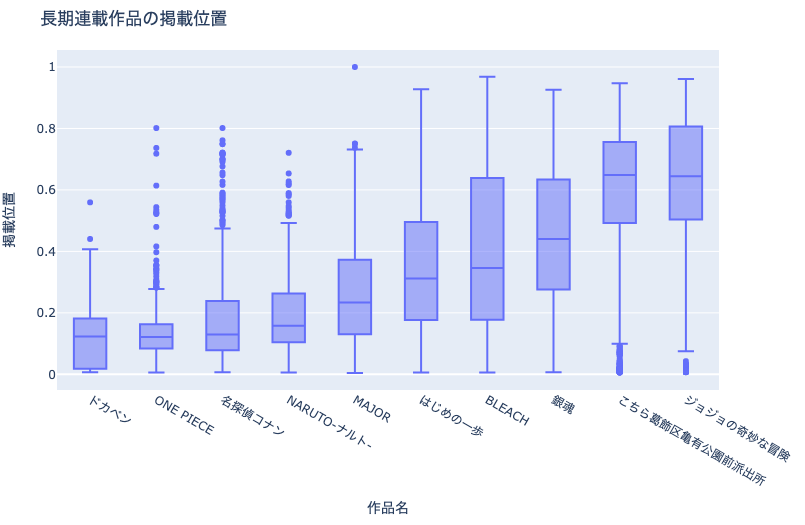
例えば上図は,作品ごとの掲載位置の分布を示した箱ひげ図です. ヒストグラム や 密度プロット と異なり,各作品の分布形状はわからなくなってしまいましたが,直感的な比較が可能になりました.
5.2. Plotlyによる作図方法#
Plotlyにおいては,plotly.express.box()関数で箱ひげ図を作図できます.
import plotly.express as px
fig = px.box(df, x='col_x', y='col_y')
上記の例では,dfのcol_xを横軸,col_yを縦軸に取った箱ひげ図のオブジェクトfigを作成します.
5.3. MADB Labを用いた作図例#
5.3.1. 下準備#
import pandas as pd
import plotly.express as px
import warnings
warnings.filterwarnings('ignore')
# 前処理の結果,以下に分析対象ファイルが格納されていることを想定
PATH_DATA = '../../data/preprocess/out/episodes.csv'
# Jupyter Book用のPlotlyのrenderer
RENDERER = 'plotly_mimetype+notebook'
# 平均掲載位置を算出する際の最小連載数
MIN_WEEKS = 5
def show_fig(fig):
"""Jupyter Bookでも表示可能なようRendererを指定"""
fig.update_layout(margin=dict(t=50, l=25, r=25, b=25))
fig.show(renderer=RENDERER)
df = pd.read_csv(PATH_DATA)
5.3.2. 長期連載作品の掲載位置の分布#
df_tmp = \
df.groupby('cname')['pageStartPosition']\
.agg(['count', 'mean']).reset_index()
df_tmp = \
df_tmp.sort_values('count', ascending=False, ignore_index=True)\
.head(10)
cname2position = df_tmp.groupby('cname')['mean'].first().to_dict()
df_plot = df[df['cname'].isin(list(cname2position.keys()))]\
.reset_index(drop=True)
df_plot['position'] = df_plot['cname'].apply(
lambda x: cname2position[x])
df_plot = df_plot.sort_values('position', ignore_index=True)
fig = px.box(
df_plot, x='cname', y='pageStartPosition',
title='長期連載作品の掲載位置')
fig.update_xaxes(title='作品名')
fig.update_yaxes(title='掲載位置')
show_fig(fig)
ヒストグラムや密度プロットより簡易に,作品ごとの掲載位置の分布を比較しやすくなりました.一方で,サンプル数や分布形状の情報が削ぎ落とされていることにご注意ください.
5.3.3. 長期連載作品の話数毎の掲載位置の分布#
# 話数の区切り
UNIT_EP = 200
cnames = df_plot['cname'].unique()
for cname in cnames:
df_c = df_plot[df_plot['cname']==cname].reset_index(drop=True)
df_c['eprange'] = (df_c.index + 1) // UNIT_EP * UNIT_EP
df_c['eprange'] = df_c['eprange'].apply(
lambda x: f'{x}話以降')
fig = px.box(
df_c, x='eprange', y='pageStartPosition',
title=f'{cname}の掲載位置')
fig.update_xaxes(title='話数')
fig.update_yaxes(title='掲載位置')
show_fig(fig)
こちらに関しても,比較が容易になった一方で,細かな分布形状の情報が失われていることがわかります.