16. 二次元ヒストグラム#
16.1. 概要#
二次元ヒストグラム(2D Bins) とは, 二種類 の質的変数を対象として,その分布を 色 で表現するグラフです. 文字通りヒストグラムの二次元版と捉えることもできますし,ヒートマップの一種と捉えることもできます.
データ量が非常に多いと,散布図やバブルチャートのドットが重複してしまい,解釈が難しくなることがあります. このような場合は,二次元ヒストグラムや等高線プロットを検討しましょう.
例えば上図は,雑誌別に掲載位置(横軸)と掲載週数(縦軸)の作品数を表した二次元ヒストグラムです.色が明るいほど,該当する作品が多いことを表します.
16.2. Plotlyによる作図方法#
Plotlyでは,plotly.express.density_heatmap()を用いて作図できます.
import plotly.express as px
fig = px.density_heatmap(
df, x='col_x', y='col_y')
上記の例では,dfのcol_xおよびcol_yについて,階級ごとにデータの下図を集計した二次元ヒストグラムのオブジェクトfigを作成します.
16.3. MADB Labを用いた作図例#
16.3.1. 下準備#
import pandas as pd
import plotly.express as px
import warnings
warnings.filterwarnings('ignore')
# 前処理の結果,以下に分析対象ファイルが格納されていることを想定
PATH_DATA = '../../data/preprocess/out/episodes.csv'
# Jupyter Book用のPlotlyのrenderer
RENDERER = 'plotly_mimetype+notebook'
# 連載週数の最小値
MIN_WEEKS = 5
def show_fig(fig):
"""Jupyter Bookでも表示可能なようRendererを指定"""
fig.update_layout(margin=dict(t=50, l=25, r=25, b=25))
fig.show(renderer=RENDERER)
df = pd.read_csv(PATH_DATA)
16.3.2. 作品別の平均掲載位置と連載週数#
df_plot = \
df.groupby('cname')['pageStartPosition'].\
agg(['count', 'mean']).reset_index()
df_plot.columns = ['cname', 'weeks', 'position']
df_plot = \
df_plot[df_plot['weeks'] >= MIN_WEEKS].reset_index(drop=True)
fig = px.density_heatmap(
df_plot, x='position', y='weeks',
title='作品別の平均掲載位置と掲載週数')
fig.update_xaxes(title='平均掲載位置')
fig.update_yaxes(title='掲載週数')
show_fig(fig)
このままでは少し見づらいので,表示範囲を変更します.
fig.update_yaxes(range=[0, 200])
show_fig(fig)
平均掲載位置と掲載週数の大まかな分布を理解することができました. 一方で,散布図で表現できていた個別のデータの情報が欠落してしまうことにご注意ください.
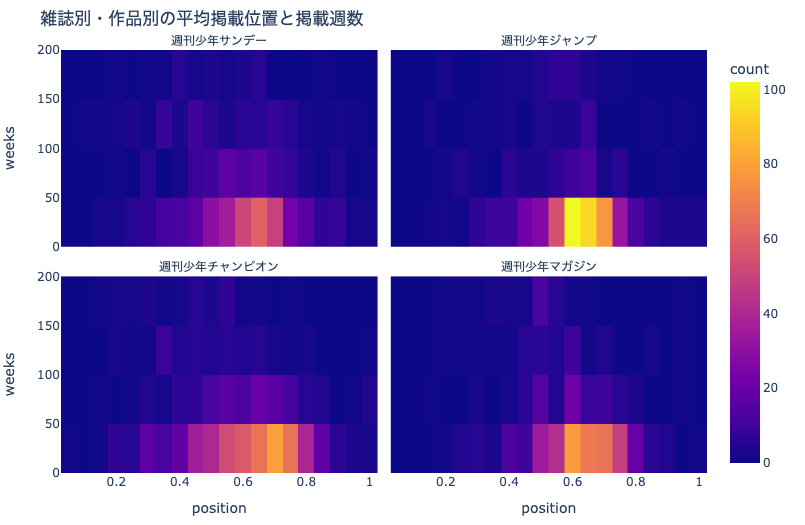
16.3.3. 雑誌別・作品別の平均掲載位置と掲載週数#
df_plot = \
df.groupby(['mcname', 'cname'])['pageStartPosition'].\
agg(['count', 'mean']).reset_index()
df_plot.columns = \
['mcname', 'cname', 'weeks', 'position']
df_plot = df_plot.sort_values(
'mcname', ignore_index=True)
df_plot = \
df_plot[df_plot['weeks'] >= MIN_WEEKS].reset_index(drop=True)
fig = px.density_heatmap(
df_plot, x='position', y='weeks',
facet_col='mcname', facet_col_wrap=2,
title='雑誌別・作品別の平均掲載位置と掲載週数')
fig.for_each_annotation(
lambda a: a.update(text=a.text.split("=")[-1]))
fig.update_yaxes(range=[0, 200])
show_fig(fig)
二次元ヒストグラムでは,散布図のように雑誌別の集計結果を重複して表示できません.
facet_colオプションを使って,サブプロットとして作図しました.