17. 等高線プロット#
17.1. 概要#
等高線プロット(Density Contours) は, 二種類 の質的変数を対象として,その分布をカーネル密度推定による 曲線 (等高線)で表現するグラフです. 二次元ヒストグラムがヒストグラムの二次元版だとすると,等高線プロットは密度プロットの二次元版と捉えることができます.
二次元ヒストグラムと同様,散布図やバブルチャートではドットが重複してしまうほどデータ量が多いとき,特に効果的です. 二次元ヒストグラムより豊かに分布の形状を表現可能ですが,等高線はあくまで 推定値 であることに注意が必要です.
例えば上図は,雑誌別に平均掲載位置(横軸)と掲載週数(縦軸)の作品数の分布を表した等高線プロットです. 等高線上の数値は,曲線上に存在する(と推定される)作品数を表します. 色が明るい領域ほど,多くの作品が存在しています.
17.2. Plotlyによる作図方法#
Plotlyでは,plotly.express.density_contour()を用いて作図できます.
import plotly.express as px
fig = px.density_heatmap(
df, x='col_x', y='col_y')
上記の例では,dfのcol_xおよびcol_yについて,階級ごとにデータの下図を集計した等高線プロットのオブジェクトfigを作成します.
fig.update_traces(
contours_coloring="fill",
contours_showlabels = True)
さらに上記のオプションを指定することで,
度数に応じた色の塗り分け
等高線への度数の付記
により視認性が向上します
17.3. MADB Labを用いた作図例#
17.3.1. 下準備#
import pandas as pd
import plotly.express as px
import warnings
warnings.filterwarnings('ignore')
# 前処理の結果,以下に分析対象ファイルが格納されていることを想定
PATH_DATA = '../../data/preprocess/out/episodes.csv'
# Jupyter Book用のPlotlyのrenderer
RENDERER = 'plotly_mimetype+notebook'
# 連載週数の最小値
MIN_WEEKS = 5
def show_fig(fig):
"""Jupyter Bookでも表示可能なようRendererを指定"""
fig.update_layout(margin=dict(t=50, l=25, r=25, b=25))
fig.update_layout(legend={
'yanchor': 'top',
'xanchor': 'left',
'x': 0.01, 'y': 0.99})
fig.show(renderer=RENDERER)
df = pd.read_csv(PATH_DATA)
17.3.2. 作品別の平均掲載位置と掲載週数#
df_plot = \
df.groupby('cname')['pageStartPosition'].\
agg(['count', 'mean']).reset_index()
df_plot.columns = ['cname', 'weeks', 'position']
df_plot = \
df_plot[df_plot['weeks'] >= MIN_WEEKS].reset_index(drop=True)
fig = px.density_contour(
df_plot, x='position', y='weeks',
title='作品別の平均掲載位置と掲載週数')
fig.update_xaxes(title='平均掲載位置')
fig.update_yaxes(title='掲載週数')
# 色を塗りつぶし,等高線にラベルを追加
fig.update_traces(
contours_coloring="fill",
contours_showlabels = True)
show_fig(fig)
このままでは少し見づらいので,表示範囲を変更します.
fig.update_yaxes(range=[0, 200])
show_fig(fig)
二次元ヒストグラムの結果と見比べて,表現力が豊かであることが確認できます.
17.3.3. 雑誌別・作品別の平均掲載位置と連載週数#
df_plot = \
df.groupby(['mcname', 'cname'])['pageStartPosition'].\
agg(['count', 'mean']).reset_index()
df_plot.columns = \
['mcname', 'cname', 'weeks', 'position']
df_plot = df_plot.sort_values(
'mcname', ignore_index=True)
df_plot = \
df_plot[df_plot['weeks'] >= MIN_WEEKS].reset_index(drop=True)
fig = px.density_contour(
df_plot, x='position', y='weeks', color='mcname',
title='雑誌別・作品別の平均掲載位置と掲載週数')
fig.update_xaxes(title='平均掲載位置')
fig.update_yaxes(title='掲載週数')
fig.update_yaxes(range=[0, 200])
show_fig(fig)
contours_coloring="fill"オプションを指定しなければ,重ねて描画することも可能です.
しかし,上記のように重複する場合は見づらくなってしまうので, 重複の少ない 複数の分布に対して使うことをおすすめします.
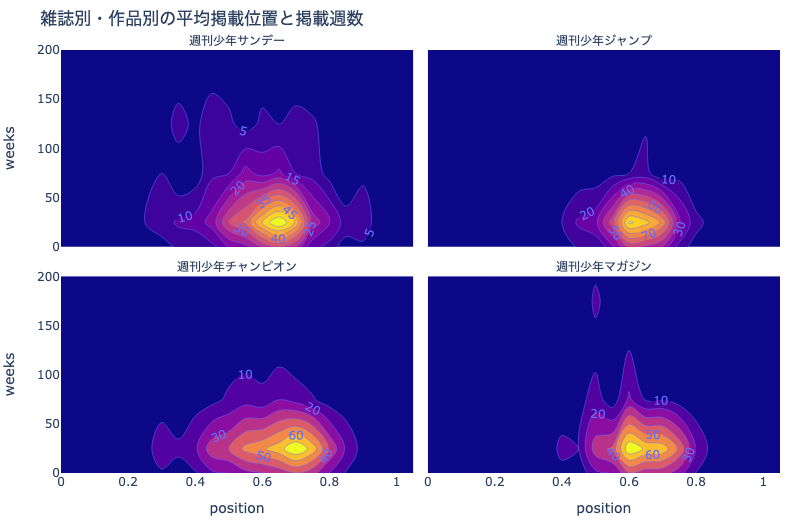
fig = px.density_contour(
df_plot, x='position', y='weeks',
facet_col='mcname', facet_col_wrap=2,
title='雑誌別・作品別の平均掲載位置と掲載週数')
fig.for_each_annotation(
lambda a: a.update(text=a.text.split("=")[-1]))
# 色を塗りつぶし,等高線にラベルを追加
fig.update_traces(
contours_coloring="fill",
contours_showlabels = True)
fig.update_yaxes(range=[0, 200])
# カラーバーの表示が壊れるので非表示
fig.update_traces(showscale=False)
show_fig(fig)
このデータセットに関しては,雑誌別に等高線プロットを描いた方が良いでしょう.
ただし,サブプロットを用いる場合は,隣接しない変数同士の比較が難しくなることにご注意ください.
例えば,週刊少年サンデーと週刊少年ジャンプを ひと目で 比較することができますか?