
5. 量を見る#
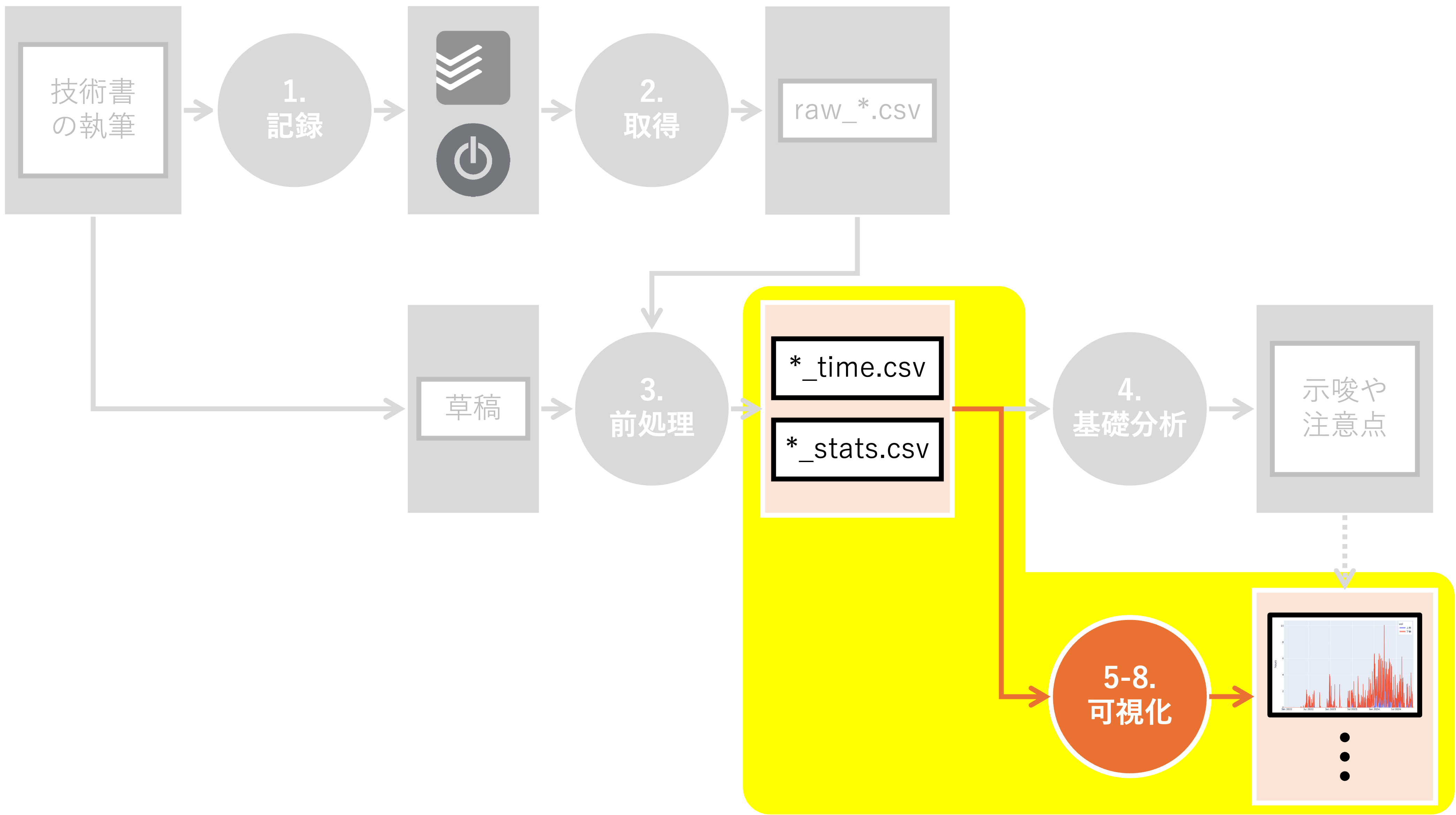
Summary
カテゴリとしては、原稿執筆(約900時間)、校正校閲(約108時間)、プロトタイピング(約75時間)の順に作業時間が長い
原稿執筆の中では、上巻3-4章(約142時間)、上巻1-2章(約115時間)、下巻5-6章(約106時間)の順に作業時間が長い
2023年11月から2024年4月までの土日に、とくに作業時間が増大した
ここからは、本書で取り上げる可視化手法を用いて分析を進めます。 まずは「量を見る」ための可視化手法です。 本書に倣い、以下の手法を紹介します。
5.1. 環境構築#
必要なライブラリをインポートし、変数を定義します。
Show code cell content
# jpholidayを事前にインストール
!pip install jpholiday
Requirement already satisfied: jpholiday in /opt/conda/lib/python3.11/site-packages (1.0.3)
Show code cell content
# itertoolsモジュールのインポート
# 様々なパターンのループを効率的に実行可能
import itertools
# reモジュールのインポート
# 正規表現に関する処理を実行
import re
# pathlibモジュールのインポート
# ファイルシステムのパスを扱う
from pathlib import Path
# jpholidayモジュールのインポート
# 日本の祝日を判定する際に使う
import jpholiday
# numpy:数値計算ライブラリのインポート
# npという名前で参照可能
import numpy as np
# pandas:データ解析ライブラリのインポート
# pdという名前で参照可能
import pandas as pd
# plotly.expressのインポート
# インタラクティブなグラフ作成のライブラリ
# pxという名前で参照可能
import plotly.express as px
# plotly.graph_objectsからFigureクラスのインポート
# 型ヒントの利用を主目的とする
from plotly.graph_objects import Figure
Show code cell content
# 可視化対象が保存されているディレクトリのパス
DIR_IN = Path("../../data/tmp")
# 草稿が保存されているディレクトリのパス
DIR_DRAFT = Path("../../data/input")
# 執筆時間を格納したファイル名
FN_WRITING = "writing_time.csv"
Show code cell content
# 質的変数の描画用のカラースケールの定義
# Okabe and Ito (2008)基準のカラーパレット
# 色の識別性が高く、多様な色覚の人々にも見やすい色組み合わせ
# 参考URL: https://jfly.uni-koeln.de/color/#pallet
OKABE_ITO = [
"#000000", # 黒 (Black)
"#E69F00", # 橙 (Orange)
"#56B4E9", # 薄青 (Sky Blue)
"#009E73", # 青緑 (Bluish Green)
"#F0E442", # 黄色 (Yellow)
"#0072B2", # 青 (Blue)
"#D55E00", # 赤紫 (Vermilion)
"#CC79A7", # 紫 (Reddish Purple)
]
Show code cell content
# plotlyの描画設定の定義
# plotlyのグラフ描画用レンダラーの定義
# Jupyter Notebook環境のグラフ表示に適切なものを選択
RENDERER = "plotly_mimetype+notebook"
Jupyter Book上に図をきれいに出力するために、以下の関数を定義しておきます。
Show code cell content
def show_fig(fig: Figure) -> None:
"""
所定のレンダラーを用いてplotlyの図を表示
Jupyter Bookなどの環境での正確な表示を目的とする
Parameters
----------
fig : Figure
表示対象のplotly図
Returns
-------
None
"""
# 図の周囲の余白を設定
# t: 上余白
# l: 左余白
# r: 右余白
# b: 下余白
fig.update_layout(margin=dict(t=25, l=25, r=25, b=25))
# 所定のレンダラーで図を表示
fig.show(renderer=RENDERER)
事前に分析対象ファイルを読み込みます。
また、date列を基準に年、月、曜日列を追加します。
Show code cell content
# pd.to_datetime()関数を用いて、"date"列を日付型に変換
df = pd.read_csv(DIR_IN / FN_WRITING)
# 年、月、日、曜日、祝日情報をdate列から取得
df["date"] = pd.to_datetime(df["date"])
df["year"] = df["date"].dt.year
df["month"] = df["date"].dt.month
df["weekday"] = df["date"].dt.weekday
df["is_holiday"] = df.apply(
lambda row: jpholiday.is_holiday(row["date"]) or row["weekday"] in [5, 6], axis=1
)
5.2. 棒グラフ#
棒グラフは、質的変数の量を視覚的に表現するための最も基本的な手法の一つです。 文字通り「棒の長さ」で各カテゴリの量を表すことで、カテゴリ間の大小関係を直感的に伝えることができます。
Show code cell source
# categoryごとにseconds列を合計し、3600で割ることで時間に変換
df_bar = (df.groupby("category")["seconds"].sum() / 3600).reset_index(name="hours")
# 可視化用に列名を変更
df_bar = df_bar.rename(columns={"category": "カテゴリー名", "hours": "合計作業時間"})
# 折れ線グラフを作成して表示
fig = px.bar(df_bar, x="カテゴリー名", y="合計作業時間")
show_fig(fig)
上図は、カテゴリー別の合計作業時間を表現した棒グラフです。 左から時系列順に並べています。
各カテゴリーの定義は以下の通りです:
プロトタイピング:本書の前身であるマンガと学ぶデータビジュアライゼーションのサイト設計・実装から公開までの一連の作業企画立案:技術評論社へ企画を持ち込み、本書のコンセプトおよび章・節・項レベルの目次を確定するまでの作業原稿執筆:本書の原稿執筆に直接関わる一連の作業。データ準備や可視化、草稿の執筆と提出など校正校閲:草稿の脱稿後、編集者と内容・構成・文章表現などを見直し、改善点の指摘・修正を行う作業販促:本書の販売を促進するための作業。練習問題の作成やSNSでの告知[1]など
最も時間がかかったのは原稿執筆であり、続いて校正校閲、そしてプロトタイピングが続きます。
原稿執筆については後ほど詳しく触れます。
校正校閲は想像以上に大変でした。
本書は、いたるところにキャラクター同士の会話が挟まる特殊なレイアウトを採用しています[2](下図[3]参照)。 本文・図・ソースコードだけでなく、全12種類ずつあるキャラクターのパターン、本文と連携した挿入位置などの確認が必要になりました。
おまけに(ありがたいことに)本書は上下巻合わせて約800ページの大ボリュームです。 1ページを1分で確認できたとしても、全ページチェックするのに13時間以上かかります。 ちなみに、実際には修正箇所にコメントを入れたり、画像を作り直したりするため 1ページを1分で確認することは不可能 でした。 少なくとも私の処理能力では。
プロトタイピングにも誤算がありました。
本書の前身であるマンガと学ぶデータビジュアライゼーションを引っ提げてコンテストに出場して、メディア芸術データベースの関係者の皆さまから暖かいコメントを頂きました(ありがとうございました…!)。 公開後しばらくしても、SNSで批判的なコメントは見当たりませんでした。 「あとはこの内容を 少しだけ 補強すれば書籍化できる」と想像していました。
しかし、この想定は甘かったです。 企画立案フェーズにおいて、編集者と議論の結果:
マンガだけでなく、アニメやゲームも扱う
MADBだけでなく、外部のデータソースも扱う
マンガ、アニメ、ゲームを単体で扱うだけでなく、それらを組み合わせた発展的な分析を行う
となったためです。 もう別物です。 ですが、このブラッシュアップのおかげで、今の形で本書を世に送り出すことができました。ありがとうございました。
さて、カテゴリーより細かい作業単位である「タスク」別に合計時間を見てみましょう。
Show code cell source
# task列を基準に作業秒数を集計し、3600で割ることで時間に変換
df_bar2 = (df.groupby(["task"])["seconds"].sum() / 3600).reset_index(name="hours")
# hoursを基準に種順ソート
df_bar2 = df_bar2.sort_values("hours", ignore_index=True)
# 可視化用に列名を変更
df_bar2 = df_bar2.rename(columns={"task": "タスク名", "hours": "合計作業時間"})
# 折れ線グラフを作成して表示
fig = px.bar(df_bar2, y="タスク名", x="合計作業時間", orientation="h", height=600)
show_fig(fig)
原稿執筆に絞って可視化してみましょう。
Show code cell source
# categoryが原稿執筆のレコードを対象に、task列を基準に作業秒数を集計し、3600で割ることで時間に変換
df_bar3 = (
df[df["category"] == "原稿執筆"].groupby(["task"])["seconds"].sum() / 3600
).reset_index(name="hours")
# hoursを基準に種順ソート
df_bar3 = df_bar3.sort_values("hours", ignore_index=True)
# 可視化用に列名を変更
df_bar3 = df_bar3.rename(columns={"task": "タスク名", "hours": "合計作業時間"})
# 折れ線グラフを作成して表示
fig = px.bar(df_bar3, y="タスク名", x="合計作業時間", orientation="h", height=500)
show_fig(fig)
上図は、原稿執筆タスク別の合計作業時間を表現した棒グラフです。 「上巻3-4章執筆」等、複数の章が集約されたタスクが存在するのは、執筆作業中に章構成が変化したためです。 詳細はデータの記録を参照ください。
上巻3-4章執筆には、特に苦労したことを覚えています。 ここでは、マンガデータを対象に、データ可視化の全プロセスをさらう形でハンズオンを作成する必要がありました。
テーマとしてはプロトタイプと重複しておりますので、早々に片付ける想定でした。 しかし、上記を改めて見返してみると、マンガデータを用いた可視化例にムラが目立ちます。 特に後半部分は「だから何?」と言った可視化結果が並び、改善の余地があると感じました。 加えて、データ分析の目的が見えづらく、本として一貫したストーリーを語りづらいとも感じました。 そこで、泣く泣く一から可視化例を練り直すことになります。
前述した課題を解決するため、本書のハンズオンでは仮説ドリブンのデータ可視化を採用しました。 つまり、分析者が持つ仮説を、データ可視化を用いて確かめる[4]形で物語を展開するのです。 そして、物語を推進するドライバーとして、 Aさん [5] と N博士 [6] というキャラクターを考案ました。 マンガに対してドメイン知識を持つAさんと、データ可視化に造詣の深いN博士がやりとりすることで、 なんとか本としての体をなすようになりました(と信じています)。
私は絵が描けませんので、キャラクターのイラストは編集者経由でイラストレーターに依頼することになりました。 伝言ゲームによる齟齬を回避するため、それぞれ立ち絵と12パターンの表情原案を作成しました。 手元に本書がある方は、どの表情が対応しているか探してみると面白いかもしれません。
ラフ案を頂いたとき、あまりの上手さに感動したことを覚えています。 この場で改めてお礼を言わせてください。ありがとうございました!


上巻3-4章の作業時間が長くなった理由には、本書の執筆プロセスも関連しています。 本書の執筆においては、いわゆるマークダウン形式の草稿に先んじて、Jupyter Bookによる草稿を完成させました。 実は、現在公開されているサポートサイトは、このJupyter Book版の草稿からマークダウンセルを削除したものです[7]。
このような進め方を採用した理由は、以下3点です:
可視化内容とそれに対する解説を、編集者と早めに固めたかった
Jupyter Bookでビルドするとそれなりの見た目になるため、モチベーション維持に役立った
もともとソースコードは全て公開予定だった
上巻1-2章にはデータ分析作業は含まれないため、一番最初に形になったのは上巻3-4章(上図2章)です。 何でも、最初に作るものには時間がかかります。 うまくTime trackingできませんでしたが、おそらくJupyter Book自体の設定に関する試行錯誤も含まれているのではないかと想像します。
5.3. 集合棒グラフ#
集合棒グラフは、複数の質的変数を同時に扱う場面で有力な手法です。 親要素内の子要素の量を並列に表示します。 子要素間の絶対量の比較が容易になることが特徴です。
Show code cell source
# category列とis_holiday列を基準にseconds列を集計し、3600で割って時間に変換
df_gbar2 = (df.groupby(["category", "is_holiday"])["seconds"].sum() / 3600).reset_index(
name="hours"
)
# 可視化用に平日/休日という列を追加し、weekend列を基準に平日か土日を判断
df_gbar2["作業日"] = df_gbar2["is_holiday"].apply(lambda x: "休日" if x else "平日")
# 可視化用に列名を日本語のわかりやすいものに変換
df_gbar2 = df_gbar2.rename(columns={"category": "カテゴリー", "hours": "合計作業時間"})
# barmode="group"を指定することで集合棒グラフを作成し、可視化
fig = px.bar(
df_gbar2,
x="カテゴリー",
y="合計作業時間",
color="作業日",
barmode="group",
color_discrete_sequence=OKABE_ITO,
)
show_fig(fig)
上図は、カテゴリーごと、作業日の種類ごとの合計作業時間を表現した集合棒グラフです。 ここで「休日」とは、土日あるいは祝日を指します。
プロトタイピング、企画立案、そして校正校閲に関しては平日の作業時間の方が多いように見えますが、原稿執筆に関してはその逆のようです。 参考までに、データ中の平日と休日の日数を確認してみましょう。
Show code cell content
# is_holidayごとのユニークな日付数をカウント
df.groupby("is_holiday")["date"].nunique().reset_index()
| is_holiday | date | |
|---|---|---|
| 0 | False | 504 |
| 1 | True | 265 |
作業実績のある日数を比較すると、平日が休日より2倍弱ほど多いことがわかります。 このことから、原稿執筆は休日を中心に腰を据えて進めていたことが理解できます。
5.4. 積上げ棒グラフ#
積上げ棒グラフは、集合棒グラフと同様に複数の質的変数を扱う手法です。 ただし、子要素の量を並列に配置するのではなく、直列に積み上げる点に特徴があります。 親要素内の子要素の構成比を表現する際に適しています。
Show code cell source
# df_gbar2をコピーして利用
df_sbar2 = df_gbar2.copy()
# カテゴリーごとの合計作業時間を積上げ棒グラフで表現
fig = px.bar(
df_sbar2,
x="カテゴリー",
y="合計作業時間",
color="作業日",
barmode="stack",
color_discrete_sequence=OKABE_ITO,
)
show_fig(fig)
上図は、カテゴリーごと、作業日の種類ごとの合計作業時間を表現した積上げ棒グラフです。 集合棒グラフと比較して、各カテゴリーの合計作業時間を比較しやすくなりました。
5.5. ヒートマップ#
ヒートマップは、二つの質的変数の組合せに対する量を、色の濃淡を用いて直感的に表現する手法です。 複雑な関係性を一目で把握しやすいという点に強みがあります。 全体像を俯瞰したり、パターンを掴んだりする際に重宝する手法です。
Show code cell source
# YYYY-MM形式で年月を格納する列を追加
df["YYYY-MM"] = df[["year", "month"]].apply(
lambda x: f"{x['year']}-{x['month']:02}", axis=1
)
# categoryとYYYY-MMで作業時間を合算し、3600で割って時間に変換
df_hm = (df.groupby(["category", "YYYY-MM"])["seconds"].sum() / 3600).reset_index(
name="hours"
)
# 作図用に列名を変更
df_hm = df_hm.rename(columns={"category": "カテゴリー", "hours": "合計作業時間", "YYYY-MM": "月"})
# ビン数をデータから取得
nbinsx = df_hm["月"].nunique()
# ヒートマップを作成
fig = px.density_heatmap(df_hm, x="月", y="カテゴリー", z="合計作業時間", nbinsx=nbinsx)
show_fig(fig)
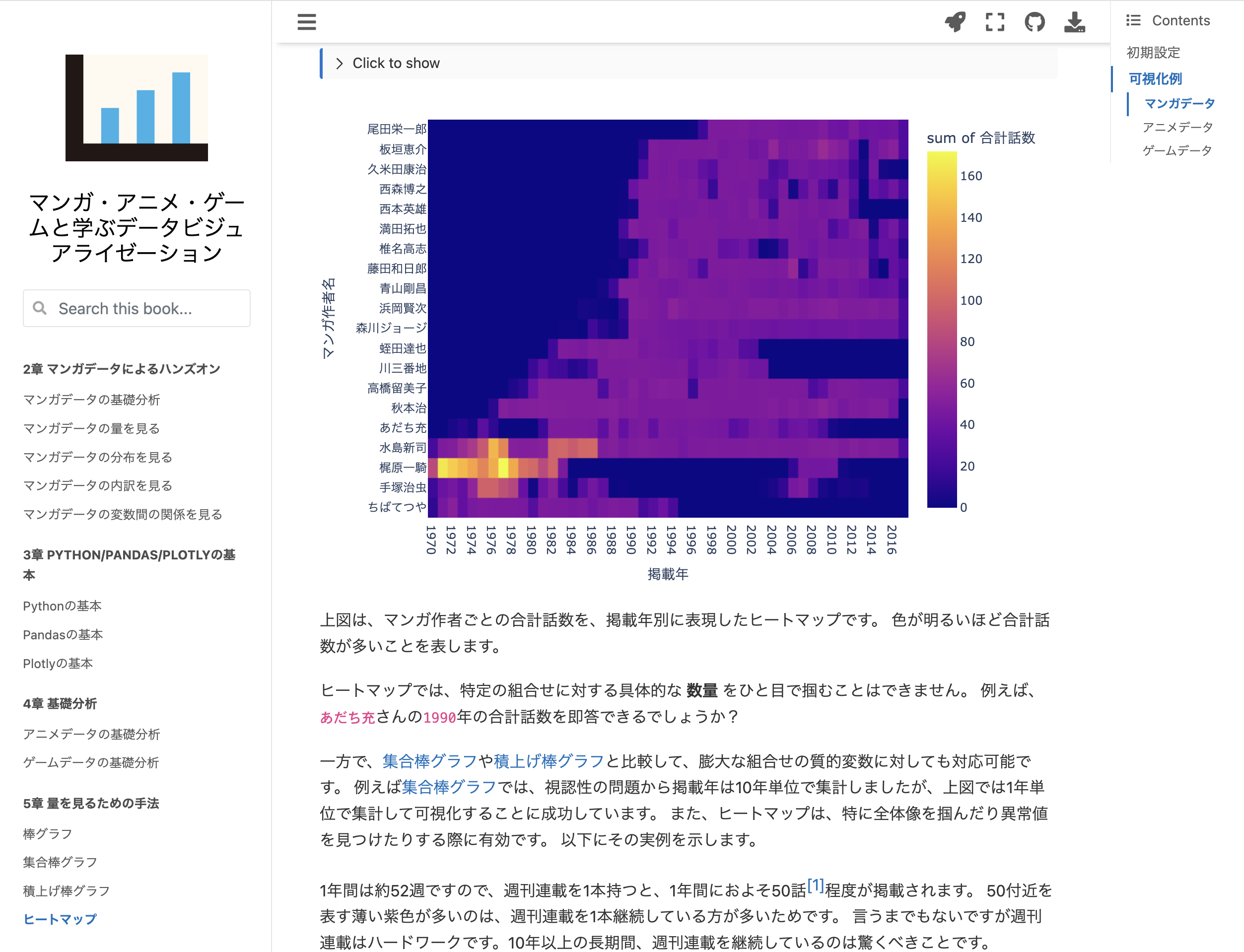
上図は、月別・カテゴリー別の合計作業時間を表現したヒートマップです。 合計作業時間が多いほど、色が明るくなるように調整しています。
大まかに、以下のようにフェーズが移り変わる様子が見て取れます:
プロトタイピング:2021年12月-2022年2月
企画立案:2022年3月-2022年4月
原稿執筆:2022年4月-2024年11月
校正校閲:2024年12月-
販促:2025年12月-
また、期間全体を通して2023年11月から2024年8月頃の原稿執筆に、集中的に時間を割いていることもわかります。 では、原稿執筆内のタスク別の変遷を見てみましょう。
Show code cell source
# 「章執筆」を含むtaskのみ抽出し、taskとYYYY-MMを基準に合計作業時間を集計
df_hm2 = (
df[df["task"].apply(lambda x: "章執筆" in x)]
.groupby(["task", "YYYY-MM"])["seconds"]
.sum()
/ 3600
).reset_index(name="hours")
# 作図用に列名を変更
df_hm2 = df_hm2.rename(columns={"task": "タスク", "hours": "合計作業時間", "YYYY-MM": "月"})
# ビン数をデータから取得
nbinsx = df_hm2["月"].nunique()
# ヒートマップを作成
fig = px.density_heatmap(df_hm2, x="月", y="タスク", z="合計作業時間", nbinsx=nbinsx)
show_fig(fig)
上図は、月別・タスク別の合計作業時間の推移を表現したヒートマップです。
特に 章執筆という文字列をタスク名に含むもののみ抽出しました。
最初に草稿に着手したのは上巻0章、つまり 前付け でした。 「前付け」とは目次より前に配置される導入部分です。 今回は本書の背景、目的、前提、スコープ、構成、再現方法等を取り扱います。 他の章に影響の受けづらく、かつ分量も多くありません。 最初に取り組む章として適切と判断しました。
次に着手したのは 上巻1-2章 です。 これらの章では、データ可視化に関する教科書的な知識を総ざらいします。 例えば、データ可視化の定義、目的、分類、ツール、関連領域、構成要素、手法、歴史、そして留意点などです。 大量の文献調査が必要になり、かつ他の章の内容に影響を与えやすいため、優先して作業を進めました。 2022年終盤頃まで集中して上巻1-2章の草稿を仕上げ、その後、Jupyter Book版の草稿に着手しました。
Jupyter Book版の草稿が完成したのは2024年3月初旬です。
この付近で複数の章に対して集中的に作業時間が増していることがわかるかと思います。
めでたく編集者と書籍全体像に合意できていましたので、マークダウン版の草稿に着手しました。
基本的には.ipynbを.mdに清書するだけですので、すぐに脱稿する予定でした…。
しかし実際には、以下のような修正が必要[8]になりました:
分冊化:前述ましたが、分量の問題から分冊化することになりました。これにより上巻と下巻を接続する 上巻7章 を新たに執筆する作業が発生しました。
会話の追加:文字ばかりで読みづらくなることを避けるため、AさんとN博士の会話文を追加することになりました。例えば以下のようなものです。

作業量のイメージを掴んで頂くため、本書中の会話文を数を確認してみましょう。
Show code cell content
# マークダウンファイル中の会話文の挿入回数を数え上げる関数
def count_chat_images(file_path):
with open(file_path, "r", encoding="utf-8") as file:
content = file.read()
return len(re.findall(r"!\[\]\(images/.*?/chat/.*?\.png\)", content))
# 草稿のファイルパス一覧
ps_draft = sorted(list(DIR_DRAFT.glob("*/*.md")))
# 草稿中の会話文の数を格納したDataFrameを作成
chats = []
for p_draft in ps_draft:
num_chats = count_chat_images(p_draft)
vol = p_draft.parts[-2]
sec = p_draft.parts[-1].replace(".md", "")
chats.append(
{
"vol": vol,
"sec": sec,
"num_chats": num_chats,
}
)
df_chats = pd.DataFrame(chats)
# 集計結果を表示
df_chats
| vol | sec | num_chats | |
|---|---|---|---|
| 0 | vol1 | 00 | 2 |
| 1 | vol1 | 01 | 34 |
| 2 | vol1 | 02 | 55 |
| 3 | vol1 | 03 | 49 |
| 4 | vol1 | 04 | 115 |
| 5 | vol1 | 05 | 90 |
| 6 | vol1 | 06 | 78 |
| 7 | vol1 | 07 | 51 |
| 8 | vol2 | 00 | 2 |
| 9 | vol2 | 01 | 66 |
| 10 | vol2 | 02 | 81 |
| 11 | vol2 | 03 | 89 |
| 12 | vol2 | 04 | 95 |
| 13 | vol2 | 05 | 52 |
| 14 | vol2 | 06 | 86 |
| 15 | vol2 | appendix | 0 |
合計会話文数を集計します。
Show code cell content
# 各章の会話文数を合計
df_chats["num_chats"].sum()
945
集計すると、 945 の会話文がありました。 全て確認したわけではありませんが、おそらくどの見開きにもN博士かAさんがいると思います。
次は、月別・曜日別の作業時間のヒートマップを見てみましょう。
Show code cell source
# weekdayとYYYY-MMを基準に作業秒数を集計し、3600で割って時間に変換
df_hm2 = (df.groupby(["weekday", "YYYY-MM"])["seconds"].sum() / 3600).reset_index(
name="hours"
)
# weekdayと曜日を対応付ける辞書
weekday2yobi = {0: "月", 1: "火", 2: "水", 3: "木", 4: "金", 5: "土", 6: "日"}
# weekdayを元に、weekday2yobiを用いてyobi列に曜日表現を格納
df_hm2["yobi"] = df_hm2["weekday"].map(weekday2yobi)
# 作図用に列名を変更
df_hm2 = df_hm2.rename(columns={"yobi": "曜日", "hours": "合計作業時間", "YYYY-MM": "月"})
nbinsx = df_hm2["月"].nunique()
nbinsy = df_hm2["曜日"].nunique()
fig = px.density_heatmap(
df_hm2, x="月", y="曜日", z="合計作業時間", nbinsx=nbinsx, nbinsy=nbinsy
)
show_fig(fig)
上図は、月別・曜日別の合計作業時間を表現したヒートマップです。 直前の図と同様、色が明るいほど作業時間が多いことを表します。
2022年1月に関しては曜日を問わずに作業時間を確保できていたこと、そして2023年11月以降は土日を中心に作業時間が増加していることがわかります。 ただし、月によって曜日数に偏りがあることに注意してください。