
2. 取得#
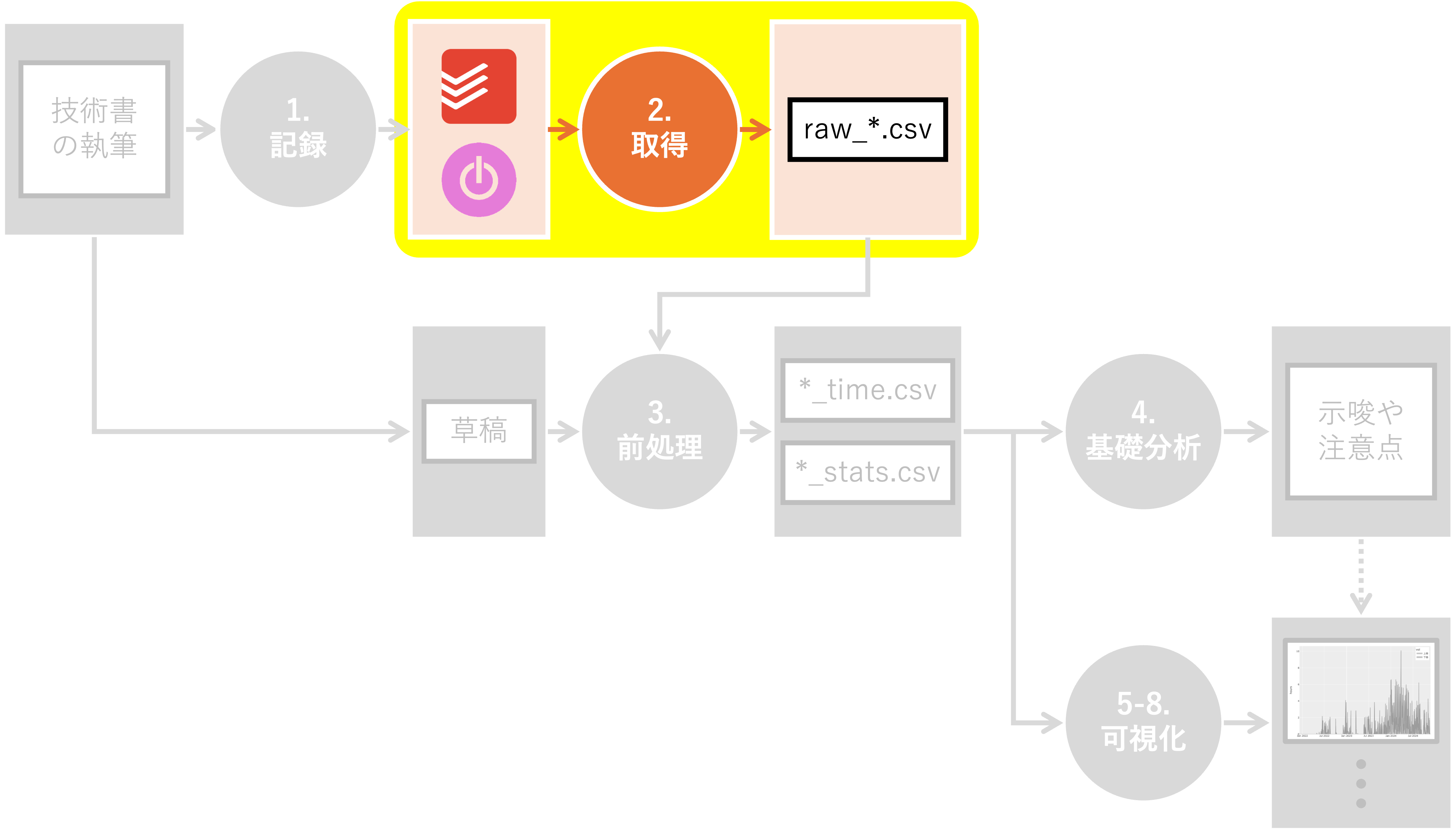
Summary
Toggl API v9を用いて、全ての作業時間と、参考までに睡眠時間のデータを取得した
24時またぎのレコードに対応するため、「終了時刻」を基準に日付を割り付けた
Toggl APIを用いて、執筆時間データを取得します。 Toggl APIは、Togglに記録されたタイムトラッキングデータにプログラムからアクセスするためのインターフェースです。 2024年12月7日現在は v9 が最新で、v8は近い将来に非推奨となる予定です。
本稿では、PythonのRequestsライブラリを使ってToggl APIにアクセスし、執筆時間データを取得する方法を紹介します。 それでは、実際のコードを見ていきましょう。
2.1. 前提#
APIを通じてデータを適切に抽出・加工するためには、Togglが保持しているデータの階層構造を理解しておく必要があります。Togglのデータは、大きく分けてWorkspace(ワークスペース)、Project(プロジェクト)、 Time Entry(タイムエントリー) の3つの階層で管理されています。
2.1.1. データの階層性#
Toggl API v9における主要な実体の関係性は以下の通りです。
Workspace: 全てのデータの最上位コンテナです。ユーザーは少なくとも1つのワークスペースに属します。
Project: ワークスペース内に作成される作業の分類単位です。各タイムエントリーは特定のプロジェクトに関連付けられます。
Time Entry: 実際に記録された「1回分」の作業記録です。具体的な作業内容(Description)、開始・終了時刻、継続時間(Seconds)などを保持します。
2.1.2. Reports API v3 のレスポンス構造#
本稿のスクリプトで使用している search/time_entries エンドポイント(Reports API v3)は、通常のAPI v9とは異なり、集計やレポート出力を目的とした特殊な構造でデータを返します。
特に注意すべきは、1つの検索結果オブジェクトの中に、実際の時間記録が time_entries というリスト形式 で格納されている点です。
フィールド名 |
説明 |
|---|---|
|
その作業が紐づくプロジェクトの識別子。 |
|
作業時に手入力したタスクの説明文。 |
|
実行データのリスト。1つのまとまった作業の中に含まれる、個別の開始・終了時間の記録が含まれます。 |
|
その作業の合計継続時間(秒単位)。 |
2.1.2.1. スクリプトでの処理#
以降で紹介するget_toggl_page 関数内では、この構造を踏まえて以下のようにデータを抽出しています。
# レスポンスの各要素(r)から必要な情報を抽出
return [
{
"project_id": r["project_id"],
"description": r["description"],
# time_entriesリストの最初の要素から終了時刻(stop)を取得
"date": extract_date(r["time_entries"][0]["stop"]),
"seconds": r["time_entries"][0]["seconds"],
"row_number": r["row_number"],
}
for r in response.json()
]
このように、APIのレスポンスは「プロジェクトや説明文でグルーピングされた結果」として返ってくるため、その中にある個別のエントリーリスト(time_entries)にアクセスして正確な日時を取得しています。
2.2. 環境構築#
まず、必要なライブラリをImportしましょう。
Show code cell content
# json: JSONデータを扱うための標準ライブラリ
import json
# time: 時間に関する関数を提供する標準ライブラリ
import time
# b64encode: Base64エンコードを行うための関数(base64モジュール)
from base64 import b64encode
# datetime: 日付と時刻を扱うための標準ライブラリ
from datetime import datetime
# Path: ファイルパスを扱うためのクラス(pathilibモジュール)
from pathlib import Path
# pandas: データ解析を効率的に行うためのサードパーティライブラリ
import pandas as pd
# requests: HTTPリクエストを送信するためのサードパーティライブラリ
import requests
# tqdm.notebook: Jupyter Notebook内で進行状況バーを表示するためのサードパーティライブラリ
from tqdm.notebook import tqdm
また、このスクリプトで使用する定数を一括で定義しておきます。 取得対象の年のリスト、クレデンシャル情報のパス、出力先ディレクトリ、データ取得処理の最大反復回数などを設定します。
Show code cell content
# 取得する年のリスト
YEARS = [2019, 2020, 2021, 2022, 2023, 2024, 2025, 2026]
# クレデンシャル情報の取得先
PATH_CRED = "../../conf/credentials.json"
# Togglの一次加工データの出力先
DIR_TOGGL = Path("../../data/tmp/toggl")
# データ取得イタレーションで用いる最大のrow_number
MAX_ITER = 100
2.3. クレデンシャルの設定#
次に、Toggl APIを利用するためのクレデンシャル情報を設定します。 クレデンシャル情報とは、APIなどのサービスにアクセスするためのユーザー認証に必要な情報のことです。 一般的には以下のような情報が該当します。
APIキー: APIを利用するために必要な英数字の文字列。APIを提供するサービスから取得します。
アクセストークン: ユーザー認証後に発行される、APIへのアクセス権を示す文字列。期限付きのものが多く見られます。
ユーザーID/パスワード: APIによっては、専用のIDとパスワードでの認証が必要な場合があります。
今回はユーザIDとパスワードを使って認証します。
これらの情報は、外部に漏れると不正利用の危険があるため、慎重に扱う必要があります。 クレデンシャル情報の管理方法としては、以下のような手段が挙げられます。
環境変数に設定する: コードに直接記載せず、環境変数として設定することで秘匿性が高まります。
ファイルに保存する: クレデンシャル情報を別ファイルに保存し、アプリケーションから読み込む方法です。
クレデンシャル管理サービスの利用: 私は利用したことがありませんが、サービスを利用して一元管理する方法もあるそうです。
今回は、ファイルに保存したクレデンシャル情報を用いて認証します。
Show code cell content
# PATH_CREDで指定したファイルパスからJSONファイルを読み込む
with open(PATH_CRED) as f:
cred = json.load(f)
# JSONファイルから、メールアドレスとパスワードを取得する
email = cred["TOGGL_EMAIL"]
password = cred["TOGGL_PASSWORD"]
参考までに、もし環境変数からクレデンシャル情報を読み込む場合のコード例を示します。
import os
# 環境変数TOGGL_EMAILとTOGGL_PASSWORDから、メールアドレスとパスワードを取得する
email = os.environ.get('TOGGL_EMAIL')
password = os.environ.get('TOGGL_PASSWORD')
# 環境変数が設定されていない場合はエラーを発生させる
if email is None or password is None:
raise ValueError("TOGGL_EMAIL and TOGGL_PASSWORD environment variables must be set.")
読み込んだクレデンシャル情報を使って、Toggl APIにリクエストを送信します。 後段の処理のため、事前にレスポンスからワークスペースIDを取得しておきます。
Show code cell content
# Toggl APIの認証情報を取得するためのエンドポイントURLを指定
url = "https://api.track.toggl.com/api/v9/me"
# Basic認証に必要なヘッダー情報を作成
headers = {
# レスポンスのContent-Typeを指定(JSON形式)
"content-type": "application/json",
# Basic認証に必要な情報を作成
# email:passwordの形式の文字列をBase64エンコードしたものを指定
"Authorization": "Basic %s"
% b64encode(f"{email}:{password}".encode()).decode("ascii"),
}
# requests.getを使ってHTTP GET requestを送信し、レスポンスを取得
data = requests.get(url, headers=headers)
# レート制限に達した場合は待機してリトライ
if data.status_code == 402:
remaining, resets_in = check_rate_limit(data)
wait_for_rate_limit(resets_in)
data = requests.get(url, headers=headers)
# レスポンスのステータスコードを確認
# 200 OK以外の場合は例外を発生させる
data.raise_for_status()
# workspace_idを取得
workspace_id = data.json()["default_workspace_id"]
2.4. Project IDの取得#
続いて、データを取得したいプロジェクトのIDを取得します。 先ほど取得したワークスペースIDを指定してプロジェクト一覧を取得し、プロジェクト名とIDの対応関係を辞書として保持します。
Show code cell content
# ワークスペースIDを使って、プロジェクト一覧を取得するエンドポイントURLを作成
url = f"https://api.track.toggl.com/api/v9/workspaces/{workspace_id}/projects"
# Basic認証に必要なヘッダー情報を作成
headers = {
# レスポンスのContent-Typeを指定(JSON形式)
"content-type": "application/json",
# Basic認証に必要な情報を作成
# email:passwordの形式の文字列をBase64エンコードしたものを指定
"Authorization": "Basic %s"
% b64encode(f"{email}:{password}".encode()).decode("ascii"),
}
# requests.getを使ってHTTP GET requestを送信し、レスポンスを取得
data = requests.get(url, headers=headers)
# レート制限に達した場合は待機してリトライ
if data.status_code == 402:
remaining, resets_in = check_rate_limit(data)
wait_for_rate_limit(resets_in)
data = requests.get(url, headers=headers)
# レスポンスのステータスコードを確認
# 200 OK以外の場合は例外を発生させる
data.raise_for_status()
# レスポンスのJSONデータをパースして、プロジェクト一覧情報を取得
projects = data.json()
# プロジェクト名からプロジェクトIDを取得する辞書を作成
pname2pid = {r["name"]: r["id"] for r in projects}
# Kakeami_Book:本書執筆に関するプロジェクト
# 睡眠:睡眠時間を記録するためのプロジェクト(参考)
project_ids = [pname2pid["Kakeami_Book"], pname2pid["睡眠"]]
ここでは、本書の執筆に関するプロジェクトと、比較対象として睡眠時間のプロジェクトを指定しています。
2.5. Togglデータの取得#
Toggl APIには、短時間に大量のリクエストを送信することを防ぐためのRate Limitが設けられています。
レート制限に達すると、APIはHTTPステータスコード 402 を返し、一定時間が経過するまで新たなリクエストを受け付けなくなります。
本稿では、レート制限に達した場合に自動的に待機してリトライするための補助関数を用意しています。 レスポンスヘッダーに含まれる以下の情報を利用します。
ヘッダー名 |
説明 |
|---|---|
|
残りのリクエスト可能回数 |
|
制限がリセットされるまでの秒数 |
Show code cell content
def check_rate_limit(response):
"""
APIレスポンスからレート制限の状態を確認する関数
Parameters:
- response : requests.Response
Toggl APIからのレスポンスオブジェクト
Returns
- tuple[int | None, int | None]
(remaining, resets_in) のタプル
- remaining: 残りのリクエスト可能回数(取得できない場合はNone)
- resets_in: 制限がリセットされるまでの秒数(取得できない場合はNone)
"""
remaining = response.headers.get("X-Toggl-Quota-Remaining")
resets_in = response.headers.get("X-Toggl-Quota-Resets-In")
if remaining is not None:
remaining = int(remaining)
if resets_in is not None:
resets_in = int(resets_in)
return remaining, resets_in
Show code cell content
def wait_for_rate_limit(resets_in, verbose=True):
"""
レート制限のリセットを待機する関数
Parameters:
- resets_in : int | None
制限がリセットされるまでの秒数。Noneの場合はデフォルトで3600秒とする
- verbose : bool, optional
待機中のメッセージを表示するかどうか(デフォルト: True)
"""
if resets_in is None:
resets_in = 3600
wait_time = resets_in + 10
if verbose:
print(f"\n⏳ レート制限に達しました。{wait_time}秒待機します...")
time.sleep(wait_time)
if verbose:
print("待機完了。処理を再開します。")
いよいよToggl APIを使ってデータを取得します。
APIのレスポンスから必要な情報を抽出するextract_date関数と、指定した条件でデータを取得するget_toggl_page関数を定義します。
Show code cell content
def extract_date(datetime_str):
"""
日付と時刻の文字列から日付情報を抽出する関数
Parameters:
- datetime_str (str): 日付と時刻の文字列(例:'2019-02-22T22:40:53+09:00')
Returns:
- str: 日付情報(YYYY-MM-DD形式)。パースに失敗した場合はNoneを返す。
"""
try:
# 文字列をdatetimeオブジェクトに変換
datetime_obj = datetime.fromisoformat(datetime_str)
# datetimeオブジェクトから日付情報を抽出
return datetime_obj.strftime("%Y-%m-%d")
except ValueError:
# 無効な文字列形式の場合はNoneを返す
return None
Show code cell content
def get_toggl_page(
email,
password,
workspace_id,
project_ids,
start_date,
end_date,
first_row_number,
page_size=50,
):
"""
Togglからデータを取得する関数
Parameters:
- email (str): Togglアカウントのメールアドレス
- password (str): Togglアカウントのパスワード
- workspace_id (int): ワークスペースID
- project_ids (List): 抽出対象とするプロジェクトIDのリスト
- start_date (str): データ取得の開始日(YYYY-MM-DD形式)
- end_date (str): データ取得の終了日(YYYY-MM-DD形式)
- first_row_number (int): 最初に取得するrow番号
- page_size (int): レスポンスに含まれるrowの数。デフォルトで50
Returns:
- dict: Toggl APIからのレスポンスのJSONデータ
"""
# Toggl APIのエンドポイントURL
url = f"https://api.track.toggl.com/reports/api/v3/workspace/{workspace_id}/search/time_entries"
# APIリクエストのパラメータ
params = {
"user_agent": "python_api_client",
"workspace_id": workspace_id,
"project_ids": project_ids,
"start_date": start_date,
"end_date": end_date,
"first_row_number": first_row_number,
"page_size": page_size,
}
# APIリクエストを送信し、レスポンスを取得
response = requests.post(url, auth=(email, password), json=params)
# レート制限に達した場合は待機してリトライ
if response.status_code == 402:
remaining, resets_in = check_rate_limit(response)
wait_for_rate_limit(resets_in)
response = requests.post(url, auth=(email, password), json=params)
# レスポンスのステータスコードを確認
if response.status_code != 200:
print(f"API Error: {response.status_code} - {response.text[:200]}")
return []
# レスポンスが空の場合は空リストを返す
if not response.text:
return []
# レスポンスのJSONデータから必要な情報を抽出
return [
{
"project_id": r["project_id"],
"description": r["description"],
"date": extract_date(r["time_entries"][0]["stop"]),
"seconds": r["time_entries"][0]["seconds"],
"row_number": r["row_number"],
}
for r in response.json()
]
get_toggl_page関数の引数で指定した条件に基づき、Toggl APIにリクエストを送信します。
レスポンスのJSONデータから必要な情報を抽出し、リスト形式で返します。
dateの基準をエントリーの開始時刻(start)ではなく終了時刻(stop)にしたのは、睡眠時間の日付ズレを回避するためです。
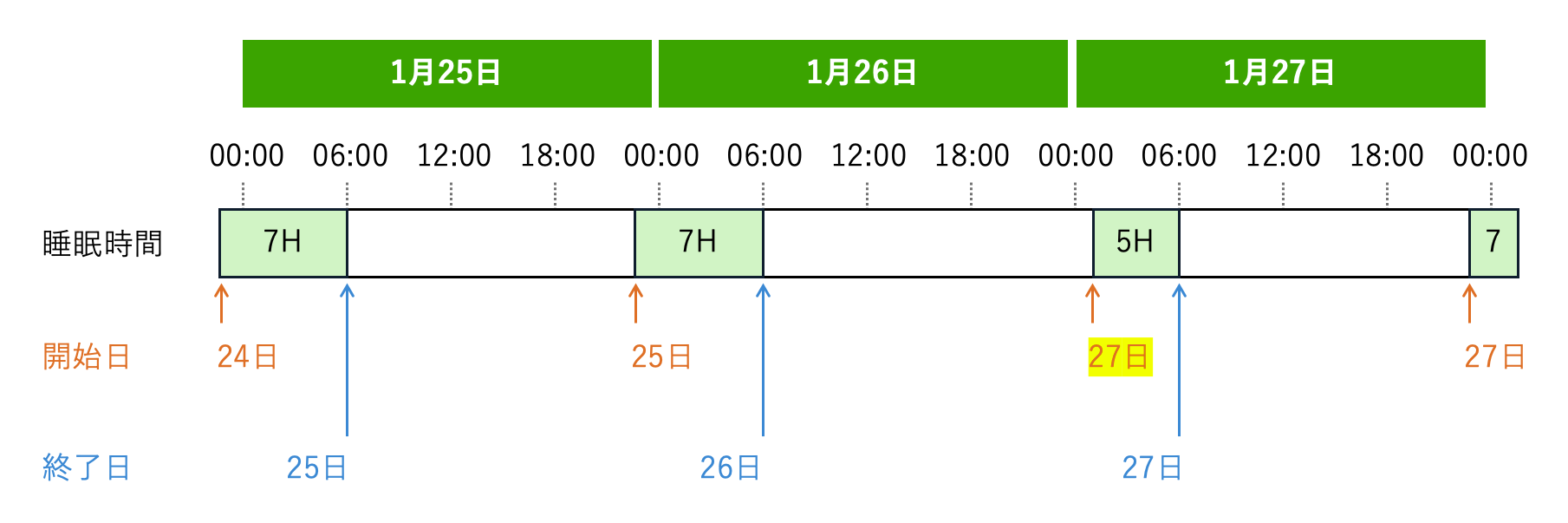
例えば、普段11時に就寝している人が、1月26日の深夜に作業に没頭し、翌27日の1時まで起きていたとします。 開始時刻を基準に日付を紐づけると、26日の合計睡眠時間が極端に短く、翌27日の睡眠時間が極端に長くなってしまいます。 これを解決するため、終了時刻を基準に日付を設定することにしました[1]。
最後に、これらの関数を使って実際にデータを取得し、CSVファイルに出力します。 あまり行儀の良い実装ではありませんので、参考程度に留めていただけますと幸いです。
Show code cell content
for year in tqdm(YEARS):
# 各年の開始日と終了日を計算
start_date = f"{year}-01-01"
end_date = f"{year}-12-31"
for i in tqdm(range(MAX_ITER), desc=f"{year}"):
# API利用制限に配慮して1秒のウェイトを入れる
time.sleep(1)
# 取得するデータの開始行番号を計算
first_row_number = i * 50 + 1
# 指定された条件でTogglからデータを取得
data = get_toggl_page(
email=email,
password=password,
workspace_id=workspace_id,
project_ids=project_ids,
start_date=start_date,
end_date=end_date,
first_row_number=first_row_number,
)
# 取得したデータが空の場合はループを終了
if not data:
break
# 取得したデータをDataFrameに変換
df = pd.DataFrame(data)
# DataFrameをCSVファイルに保存
# 最初の繰り返しではヘッダー行を含めて新規にファイルを作成し、
# それ以降の繰り返しではヘッダー行なしでファイルに追記する
mode = "w" if i == 0 else "a"
header = i == 0
path_out = DIR_TOGGL / f"raw_{year}.csv"
df.to_csv(path_out, header=header, mode=mode, index=False)
取得対象の年ごとに、開始日と終了日を設定します。
各年について、最大反復回数MAX_ITERだけAPIリクエストを送信し、取得したデータをDataFrameに変換してCSVファイルに出力します。
2回目以降は、ファイルを追記モードで開くことで、順次データを追加していきます。
以上が、Toggl APIを利用した執筆時間データの取得方法です。 次は、取得したデータを読み込み、前処理を行う方法を解説します。